主要介绍了Python实现在线程里运行scrapy的方法,涉及Python线程操作的技巧,非常具有实用价值,需要的朋友可以参考下
”Python 线程 运行 scrapy“ 的搜索结果
以下按自己的编码风格复现书本代码单线程程序主要思路:graph TDA(获取指定网页字符内容) -->B(从中筛选出所有图像url)B --> C(逐一对图像url进行预处理:拼接,去重)C --> D(逐一下载相应的图片到本地images子文件中)...
一、背景对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取进程:优点:充分利用多核CPU(能够同时进行多个操作)缺点:系统资源消耗大,重新开辟内存空间线程:优点:共享内存,IO操作...
Scrapy 框架 scrapy五大核心组件简介 提升scrapy的爬取效率 增加并发: 降低日志级别: 禁止cookie: 禁止重试: 减少下载超时: scrapy基本使用 环境安装: scrapy使用流程: 爬虫文件解析 scrapy的...
文章目录一、scrapy爬虫框架介绍在...利用现有的爬虫框架,可以提高编写爬虫的效率,而说到 Python 的爬虫框架,Scrapy 当之无愧是最流行最强大的爬虫框架了。scrapy介绍Scrapy 是一个基于 Twisted 的异步处理框架...
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,在创建了爬虫程序后,就可以运行爬虫程序了。Scrapy中介绍了几种运行爬虫程序的方式,列举如下:-命令行工具之scrapy runspider(全局命令)-命令行工具之scrapy...
具体如下:如果你希望在一个写好的程序里调用scrapy,就可以通过下面的代码,让scrapy运行在一个线程里。"""Code to run Scrapy crawler in a thread - works on Scrapy 0.8"""import threading,Queuefrom twisted....

Python爬虫—scrapy框架
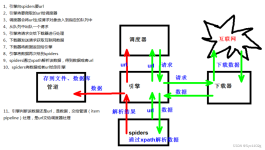
最近看scrappy0.24官方文档看的正心烦的时候,意外发现中文翻译0.24文档,简直是福利呀~ http://scrapy-chs.readthedocs.org/zh_CN/0.24/结合官方文档例子,简单整理一下:import scrapyfrom myproject.items import...
网络爬虫 网页爬虫.pptx06 Python操作MySQL数据库.pptx07 Python操作MongoDB数据库.pptx08 Python多线程 多进程开发.pptx09 Python爬虫框架Scrapy实战.pptx10 Python Web开发框架Django实战.pptx
python scrapy 多线程
# -*- coding: utf-8 -... os.system('scrapy crawl spider_name -s LOG_FILE=all.log') # 不想看到控制台打印debug信息 就加 -s LOG_FILE=all.log 【将debug信息接入all.log文件】 if __name__ == '__main__': wh.
问题的由来我们的需求为爬取红色框框内的名人(有500条记录,图片只展示了一部分)的 名字以及其介绍,关于其介绍,点击该名人的名字即可,如下图:这就意味着我们需要爬取500个这样的页面,即500个HTTP请求(暂且...
具体如下:如果你希望在一个写好的程序里调用scrapy,就可以通过下面的代码,让scrapy运行在一个线程里。"""Code to run Scrapy crawler in a thread - works on Scrapy 0.8"""import threading, Queuefrom twisted....


原标题:Python中爬虫框架或模块的区别Python中爬虫框架或模块的区别(1)爬虫框架或模块Python自带爬虫模块:urllib、urllib2 ;第三方爬虫模块:requests,aiohttp;爬虫框架: Scrapy、pyspider。(2)爬虫框架或模块的...
scrapy_多条管道下载
小伙伴们很喜欢给小编出各种难题,比如今天关于框架,有小伙伴在浏览时,看到别人咨询异步还有多线程,因为自己也...什么是多线程:多线程:允许单个任务分成不同的部分运行相互之间是有一定的相似之处的,那我们接...
文章目录前言一、爬虫必备知识二、网络协议与爬虫重点三、静态页面抓取(以CSDN论坛为例)总结 前言 目的: 尝试借助CSDN构建自己的知识学习体系 ...多线程和线程池 二、网络协议与爬虫重点 网络协议 重点掌握
win10下python3.5 scrapy安装
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。? Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类...
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都...
安装Anaconda详细介绍下载下载完整包如果日常工作或学习并不必要使用1,000多个库,那么可以考虑安装Miniconda(图形界面下载及命令行安装请戳),这里不过多介绍Miniconda的安装及使用。AnacondaAnaconda是一个包含180...
[ ] 免责声明:该项目旨在研究Python 3.6,Scrapy Spider Framework和MongoDB数据库,不能将其用于商业或其他个人目的。 如果使用不当,将由个人承担。 该项目主要用于爬网t66y.com论坛,这是世界上最大的中文BBS。 ...
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架。 用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片。 (提高请求效率) Scrapy 使用了Twisted...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地